지난번 포스팅에 이어, 이번 글에서는 1) 편향과 분산이 의미하는 바를 그림으로 쉽게 이해하고, 2) 편향, 분산과 모델 복잡도 간의 관계에 대해서 알아보도록 한다. 본 글은 고려대학교 강필성 교수님의 비즈니스 애널리틱스 강의 내용을 요약한 것이며, 해당 강의는 유튜브에서 무료로 시청이 가능하다(링크).
1. 그림으로 보는 편향과 분산

지난 번 편향-분산 분해 포스팅을 통해 우리는 위의 수식과 같이 오차 함수 MSE를 세 가지로 분해할 수 있음을 보였다. 가장 우측에 있는 sigma 제곱은 사람이 컨트롤 할 수 없는 자연발생적인 데이터의 변동성이므로 이를 제외한다고 하면, 오차를 줄일 수 있는 방법은 편향의 제곱(첫번째 텀) 또는 분산(두번째 텀)을 감소시키는 것 뿐이다. 우선, 편향과 분산이 각각 의미하는 바가 무엇인지 그림으로 쉽게(?) 알아보자.

[그림 2]를 보면 빨간색으로 네모 박스를 친 것이 정답 함수 f*를 의미한다. 우리는 Additive Error Model을 가정했으므로, 정규분포를 따르는 노이즈(epsilon)가 있고 따라서 노이즈로 인해 발생할 수 있는 데이터 영역이 정답(f*(x))을 중심으로 퍼져있게 된다. 그 부분이 파란색 동그라미 영역이다. 즉, 실제 데이터가 발생할 수 있는 영역을 의미한다.
우리는 정답인 f* 함수를 알지 못하므로 f*를 추정하는 f_hat 함수를 구하게 되는데, f_hat(x) 값(추정값)이 나타날 수 있는 영역을 나타낸 것이 바로 노란색 동그라미 영역이다. 그리고 그 값들의 기댓값, 중심을 나타내는 것이 바로 f_bar(x)인 것이다. 노란색 동그라미의 중심부분이다.
요약하자면, 파란색 영역은 실제 데이터의 영역이며 이것의 중심이 정답인 것이고, 반면에 노란색 영역은 우리가 추정한 함수가 뱉어내는 값들의 영역이며, 이것의 중심이 추정하는 값들의 기댓값인 것이다. 그림이 나타내는 주요한 개념들을 이해했다면 이를 바탕으로 편향과 분산을 직관적으로 이해해보도록 하자.
1) 편향이란?
편향이란, (노이즈가 다른) 여러 데이터셋을 바탕으로 추정값들의 중심(노란색의 중심)이 얼마나 실제 데이터의 중심(정답)과 떨어져 있는가를 의미하는 것이다. 편향이 작다는 뜻은 여러 데이터셋을 바탕으로 반복적으로 추정하는 과정을 통해 전체적인 오차를 줄일 수 있다는 뜻이다. 반면에, 편향이 크다는 것은 아무리 노력을 해도 정답을 맞출 가능성이 적다는 뜻이다.
2) 분산이란?
분산이란, (노이즈가 다른) 여러 데이터셋을 바탕으로 추정한 결과들이 그 결과들의 평균과 비교했을 때 얼마나 퍼져 있는가를 나타낸다. 분산이 작으면 노이즈가 변한다고 해서 함수의 추정값이 크게 바뀌지 않는다는 뜻이다. (f_hat(x)들끼리 모여있으니까!) 반면에 분산이 크면, 노이즈가 바뀔수록 개별적인 추정값들이 크게크게 바뀐다는 뜻이다.
3) 모델의 4가지 유형
편향과 분산 정도에 따라 학습 모델을 [그림 3]과 같이 4가지 유형으로 분류해 볼 수 있다.
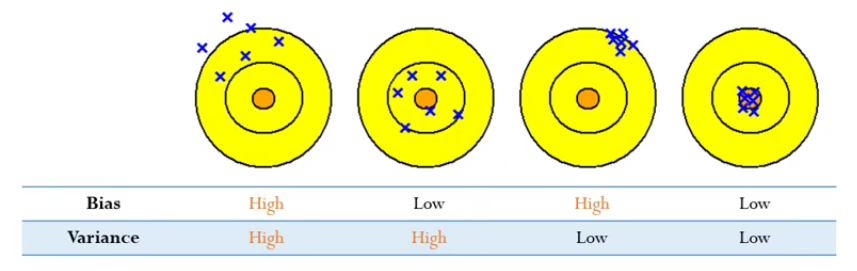
1. 높은 편향, 높은 분산: 정확도가 떨어지는 가장 쓸모 없는 유형이다.
2. 낮은 편향, 높은 분산: 추정값들이 전체적으로 정답에 가깝지만 자기들끼리는 분산되어 있는 유형이다. (Decision Tree, ANN, SVM, k-NN with small k 등)
3. 높은 편향, 낮은 분산: 추정값들끼리는 모여있지만, 전체적으로 정답과 거리가 있는 유형이다. (Logistic Regression, LDA, k-NN with large k 등)
4. 낮은 편향, 낮은 분산: 추정값들끼리 모여있으면서 동시에 정답에 가까운 유형으로 가장 바람직하다.
우리가 가장 원하는 것은 4번처럼 되는 것이다. 그러나 현실 세계의 모델은 대부분 2번 또는 3번의 형태를 가지는 경우가 많다. 따라서 2번, 3번을 4번처럼 만들도록 하는 방법론들이 많이 연구되었고, 이러한 노력의 일환으로 앙상블 학습이 고안된 것이다. 앙상블 학습에 대해서는 다음 포스팅에서 자세히 다루도록 하겠다.
2. 모델의 복잡도와 편향, 분산 간의 관계
위의 4가지 유형 중 2번과 3번의 차이를 만드는 요인에는 모델 복잡도와 관련이 깊다. 2번 유형은 보통 모델 복잡도가 높다. 반면에, 3번 모형은 복잡도가 낮은 경우가 많다. 편향-분산의 정도와 모델 복잡도가 관련이 있다는 것을 아래 그림을 통해 알아보자.

그래프 위의 검은색 선이 정답 함수(f*(x))이고, 빨간색 선이 학습 모델(f_hat(x))이다. 세번째 열의 학습 모델은 3차 다항식으로 복잡도가 높다. 이 때 맨 아래의 그래프를 보면 분산은 넓지만 편향이 작음을 볼 수 있다. 그 이유는 모델이 복잡하면 데이터에 더욱 알맞게 fitting 되면서 편향을 감소시키기 때문이다. 하지만 데이터셋마다 모델의 모양이 상대적으로 크게크게 변하기 때문에 추정값들 간의 차이, 즉 분산도 커지게 된다. 반면에, 네번째 열의 학습 모델은 1차 다항식으로 복잡도가 낮다. 이 경우 정답 데이터에 fitting이 덜 되기 때문에 편향이 상대적으로 커진다. 하지만 다른 데이터셋이 인풋으로 주어짐에도 모델의 모양이 크게 변형되지 않기 때문에 분산은 작은 것이다. 따라서 요약하자면, 모델의 복잡도가 크면 작은 편향과 높은 분산을 가지며, 반대로 모델의 복잡도가 작으면 편향은 크고 분산은 작다.
References
[1] https://www.youtube.com/watch?v=mZwszY3kQBg
'데이터과학' 카테고리의 다른 글
| [추천시스템] 비개인화 추천 알고리즘 - 인기도 기반 추천 (0) | 2021.08.30 |
|---|---|
| [머신러닝] 앙상블 학습 - 2) Bagging (0) | 2021.06.23 |
| [머신러닝] 앙상블 학습 - 1) 배경 (2) | 2021.06.14 |
| [머신러닝] 편향-분산 분해 (Bias-Variance Decomposition) (2) | 2021.05.29 |
| [통계] 커널 밀도 추정 (Kernel Density Estimation) (4) | 2021.04.27 |




댓글