[Andrew Ng 교수님의 머신러닝 전략 시리즈]
2022.01.23 - [데이터과학] - [머신러닝] 프로젝트 전략 (1): Orthogonalization
2022.01.24 - [데이터과학] - [머신러닝] 프로젝트 전략 (2): Evaluation Metric
2022.02.09 - [데이터과학] - [머신러닝] 프로젝트 전략 (3): Train / Dev / Test set
본 포스팅에서는 앤드류 응 교수님의 세번째 머신러닝 전략을 소개한다. 이번에는 Train/Dev/Test set을 어떻게 효과적으로 나눌 것인가에 대해 다룬다. 하나씩 살펴보자.
1. Dev / Test Distribution
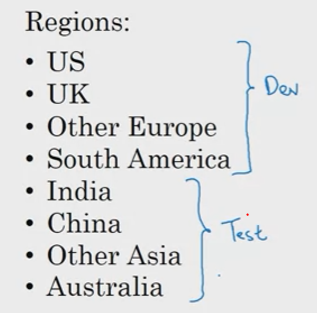
Dev set과 Test set의 분포가 같아야 한다. Dev set과 Test set의 분포가 다르면 Dev set의 분포에 맞춰 학습된 모델이 Test set에서는 잘 작동하지 않을 수 있기 때문이다. 예를 들어, 고양이 분류 모델을 만들었다고 가정하자. 그리고 [그림1]과 같이 Dev set은 8개 중 4개의 지역의 데이터셋을 포함하고 있고, Test set은 다른 4개 지역의 데이터를 포함하도록 나눈다. 이런 분리법은 Dev set과 Test set의 분포가 달라지므로 좋지 않은 방법이다. 그러므로 8개의 모든 지역으로부터 랜덤하게 샘플링하여 Dev set과 Test set을 설정하는 것이 좋다.
2. Size of the Dev and Test Sets
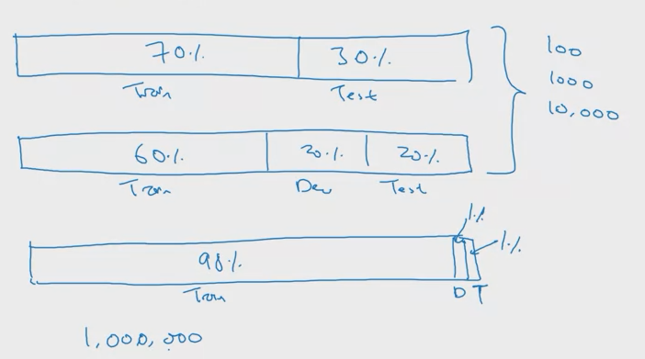
Dev와 Test set의 크기는 전체 데이터 사이즈에 따라 달라질 수 있다. [그림2]의 고전적인 방법에 따르면 전체 데이터의 70%를 학습에 사용하고 30%를 테스트에 사용했다. 혹은 학습셋 60%, Dev 와 Test set을 각각 20%씩 사용했다. 전체 데이터의 양이 적은 경우에는 Dev와 Test가 충분히 커야 검증의 신뢰성이 높아지므로 Dev/Test set의 비중이 매우 높았다. 그러나 요즘에는 데이터의 양이 방대해져서 굳이 전체 데이터 중 Dev/Test set의 비중을 많이 가져갈 필요가 없다. 예를 들어, 총 100만개의 데이터가 있는 경우, 1%만해도 10,000개가 되고 이는 모델의 성능을 평가하기에 충분한 양일 수 있다. 요약하자면, Dev/Test set의 비중은 고정된 것이 아니라 전체 데이터의 양에 따라 모델 검증에 충분할 정도로 설정하면 된다는 것이다.
3. When to Change Dev / Test Sets?
Dev와 Test set이 유사한 분포를 가지며 신뢰성 있는 검증에 충분할 정도로 적당한 크기로 나눴다고 해도, 모델이 적용되는 현실의 데이터와 다르다면 Dev/Test set을 바꿀 필요가 있다. 예를 들어, 모델 학습 및 검증에 사용한 Dev/Test set은 대부분 크기가 큰 고화질 이미지를 사용했다고 하자. 그런데 사용자들은 모바일로 서비스를 이용하기 때문에 고화질보다는 저용량, 저화질의 이미지를 주로 사용한다. 이런 경우 Dev/Test와 서비스가 적용되는 현실 데이터 간 분포의 차이가 발생한다. 모델이 Dev/Test에서는 성능이 좋을 수 있으나 현실에서는 잘 작동하지 않을 것이다. 그러므로 Dev/Test set을 현실 데이터와 유사하도록 저용량, 저화질의 이미지를 사용해야 한다.

'데이터과학' 카테고리의 다른 글
| [머신러닝] 원핫인코딩이 트리 기반 모델의 성능을 저하시키는 이유 (0) | 2023.04.05 |
|---|---|
| [머신러닝] 프로젝트 전략 (2): Evaluation Metric (0) | 2022.01.24 |
| [머신러닝] 프로젝트 전략 (1): Orthogonalization (0) | 2022.01.23 |
| [추천시스템] Multi-Armed Bandit (2) | 2021.10.18 |
| [추천시스템] Alternating Least Square (ALS)를 활용한 Matrix Factorization (7) | 2021.09.28 |




댓글