[Andrew Ng 교수님의 머신러닝 전략 시리즈]
2022.01.23 - [데이터과학] - [머신러닝] 프로젝트 전략 (1): Orthogonalization
2022.01.24 - [데이터과학] - [머신러닝] 프로젝트 전략 (2): Evaluation Metric
2022.02.09 - [데이터과학] - [머신러닝] 프로젝트 전략 (3): Train / Dev / Test set
본 포스팅에서는 앤드류 응 교수님의 두번째 머신러닝 전략을 소개한다. 이번에는 평가 지표를 어떻게 설정할 것인가에 대해 다룬다. 여러 모델을 만든 다음, 그들 중 어떤 모델이 가장 성능이 좋은지를 판단하려면 비교할 수 있는 평가 지표가 있어야 한다. 이때 평가 지표는 단 하나의 수치값이어야 한다.
1. Single Number Evaluation Metric
1) Precision, Recall, F1-score
예를 들어, 사진을 보고 고양이인지 아닌지 분류하는 모델 A와 B가 있다고 하자. A와 B는 하이퍼파라미터가 다른 모델이다. 두 모델을 테스트해보니 Classification의 성능 평가 방법으로 많이 사용되는 Precision, Recall 값이 아래와 같다. 이렇게 두 종류의 평가 지표를 나란히 두면 A와 B 중에 어떤 모델이 더 좋은지 판단하기가 어렵다. A는 Recall 관점에서 B보다 좋고, B는 Precision 관점에서 A보다 좋다. 따라서, 여러 개의 Metric을 종합해주는 하나의 값이 필요하다.
(참고로 Precision은 내가 1로 예측한 것 중에 실제 1이 얼마나 있는지 비율을 나타내고, Recall은 실제 모든 1 중에서 내가 1로 예측한 것이 얼마나 되는지 비율을 나타낸다. )
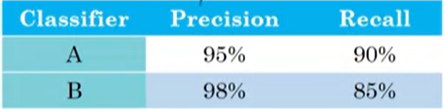
모델을 평가하는 데 있어 Precision과 Recall 모두 중요하기 때문에 하나의 값만 가지고 모델을 선택할 수 없다. 그래서 나온 것이 F1-score이다. F1-score는 Precision과 Recall의 조화평균이다 (그림2 참고). 수식 자체를 아는 것보다는 F1-score가 두 지표를 동등하게 고려하여 하나의 수치값으로 도출했다는 것이 중요하다.
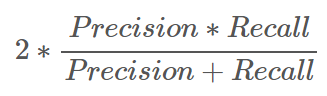
앞서 언급한 두 모델의 F1-score는 아래와 같다. 이제 우리는 Precision과 Recall을 함께 고려했을 때 모델 A가 B보다 우수하다고 결론 지을 수 있다. 이처럼 우리가 중요하게 여기는 평가 지표가 여러개 있을 때 어떻게 하면 그들을 잘 조합하여 하나의 평가 지표로 만들 것인지 고민해야 한다.

2) Another Example
F1-score의 사례를 보면 Single Number Evaluation Metric은 이미 만들어진 것만 써야하던지, 아니면 내가 정의하기에 엄청 어려울 것 처럼 느껴진다. (뭐,,, 적어도 나는 그랬다.) 하지만 우리 응 교수님은 친절하게도 정말 쉬운 예시도 알려주셨다.
그림4는 6개의 Classification 모델인 A~F의 국가별 에러값을 정리한 표이다. 4개의 Category와 6개의 모델 종류가 조합하여 총 24개의 에러값이 있는데, 이렇게만 보면 어떤 모델이 모든 국가에 대해서 성능이 제일 좋은지 판단하기가 어렵다. 그래서 가장 간단하게 각 모델별로 에러의 평균값을 오른쪽 끝에 추가해주었다. 즉, 여러 에러를 평균을 통해 하나의 평가 지표로 변환한 것이다. 그럼 다음 포스팅에서는 실제 머신러닝 프로젝트에서 어떻게 중요한 지표들을 잘 조합할 것인지에 대해 다룰 것이다.

2. Satisficing and Optimizing Metric
이어서 평가 지표를 어떻게 설정해야 하는지에 대해 더 살표보도록 하겠다. 머신러닝 모델을 평가할 때는 최적화해야 하는 Optimizing Metric과 최소한의 조건만 충족하면 되는 Satisficing Metric으로 구성된 평가 지표를 활용할 수 있다. 예를 들어, 고양이 판별 모델 A, B, C의 정확도와 실행 시간이 [그림1]과 같다고 하자. 여기서 말하는 정확도(Accuracy)는 F1-Score일 수도 있고 다른 지표일 수도 있다. Running Time은 이미지를 넣었을 때 분류 값을 출력하는 데 걸리는 시간을 의미한다.
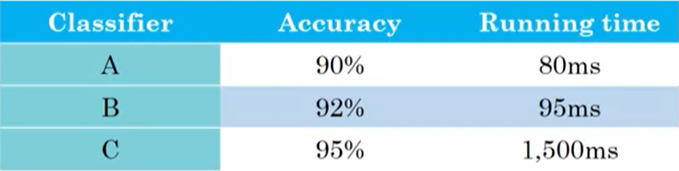
여기서 우리는 실행시간이 최대 100ms를 넘지 않으면서 동시에 정확도가 가장 높은 모델을 원한다. 즉, 정확도는 최대화되길 원하면서 실행시간은 50ms이든 80ms이든 100ms보다만 작으면 상관하지 않겠다는 것이다. 여기서 정확도는 우리가 최적화해야 하는 Optimizing Metric을 의미하고, 실행시간은 조건만 충족하면 되는 Satisficing Metric이다. 이제 기준을 적용하면 비록 C가 가장 높은 정확도를 지녔음에도 불구하고 우리는 B를 가장 좋은 모델이라고 선정하게 된다. 일반적으로 N개의 Metric이 있다고 했을 때, 1개의 가장 중요한 Optimizing Metric을 두고 나머지는 Satisficing Metric으로 간주하고 각 Metric에 대한 기준 값을 설정하도록 한다.
References
[1] https://www.coursera.org/specializations/deep-learning
심층 학습
Learn Deep Learning from deeplearning.ai. If you want to break into Artificial intelligence (AI), this Specialization will help you. Deep Learning is one of the most highly sought after skills in tech. We will help you become good at Deep Learning.
www.coursera.org
'데이터과학' 카테고리의 다른 글
| [머신러닝] 원핫인코딩이 트리 기반 모델의 성능을 저하시키는 이유 (0) | 2023.04.05 |
|---|---|
| [머신러닝] 프로젝트 전략 (3): Train / Dev / Test set (0) | 2022.02.09 |
| [머신러닝] 프로젝트 전략 (1): Orthogonalization (0) | 2022.01.23 |
| [추천시스템] Multi-Armed Bandit (2) | 2021.10.18 |
| [추천시스템] Alternating Least Square (ALS)를 활용한 Matrix Factorization (7) | 2021.09.28 |




댓글